Este artigo é uma tradução do artigo original do Heberto Graca. Todos as referências neste artigo são direcionadas aos links originais. Traduzir artigos técnicos não é algo fácil, decidi manter alguns estrangeirismos para facilitar a compreensão do texto e a busca deles para quem ainda não conhece os termos. Caso tenha alguma sugestão que torne o artigo mais fácil para ser compreendido sinta-se livre para deixar um comentário.
Este post é parte de The Software Architecture Chronicles, uma série de posts sobre Arquitetura de Software. Neles, escrevo sobre o que aprendi sobre Arquitetura de Software, como penso e como uso esse conhecimento. O conteúdo desta postagem pode fazer mais sentido se você ler as postagens anteriores desta série.
Depois de me formar na universidade, segui uma carreira como professor do ensino médio até alguns anos atrás, decidi abandonar a carreira e me tornar um desenvolvedor de software em tempo integral.
A partir daí, sempre senti que precisava recuperar o tempo “perdido” e aprender o máximo possível, o mais rápido possível. Portanto, tornei-me um pouco viciado em experimentar, ler e escrever, com foco especial em design e arquitetura de software. É por isso que escrevo essas postagens, para me ajudar a aprender.
Em minhas últimas postagens, tenho escrito sobre muitos dos conceitos e princípios que aprendi e um pouco sobre como raciocino sobre eles. Mas eu vejo isso como apenas peças de um grande quebra-cabeça.
O post de hoje é sobre como encaixar todas essas peças e, como parece que devo dar um nome, chamo-a de Arquitetura Explícita. Além disso, todos esses conceitos “passaram em seus testes de batalha” e são usados no código de produção em plataformas altamente exigentes. Uma delas é uma plataforma SaaS com milhares de lojas virtuais em todo o mundo, a outra é um marketplace, em 2 países com um message bus que lida com mais de 20 milhões de mensagens por mês.
- Blocos fundamentais do sistema
- Ferramentas
- Conectando as ferramentas e mecanismos de entrega ao Application Core
- Organização do Application Core
- Camada de Domínio
- Componentes
- Obtendo dados de outros componentes
- Fluxo de Controle
- Com um barramento de Command/Query
- Conclusão
Blocos fundamentais do sistema
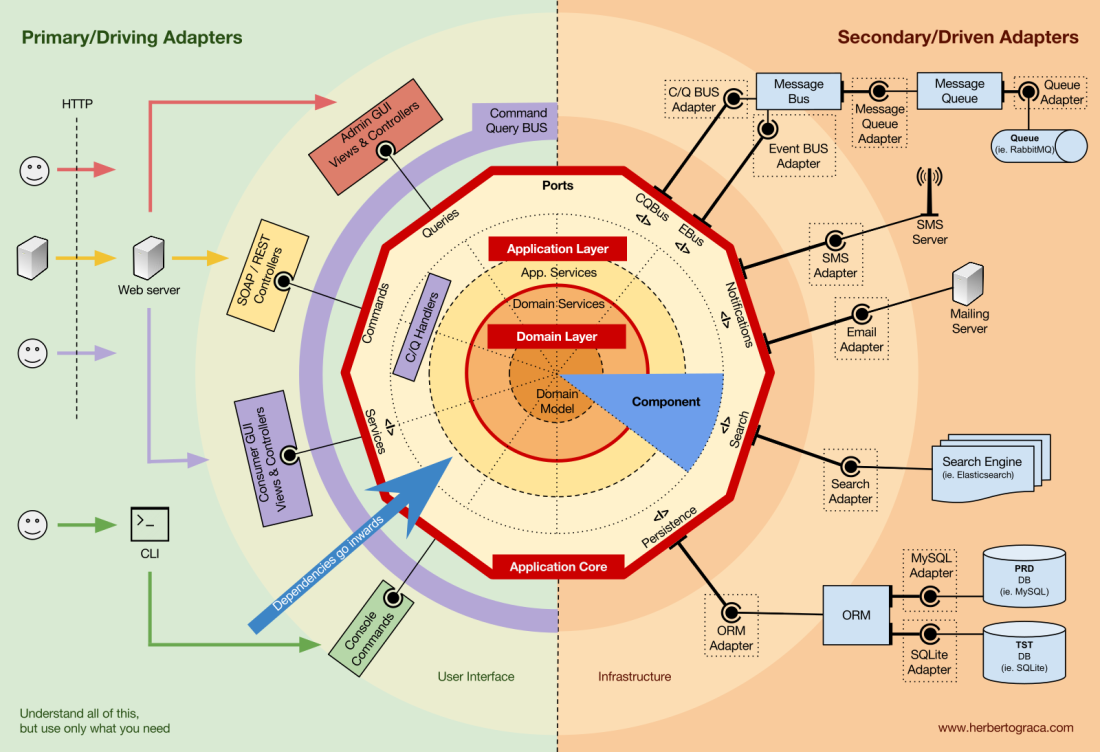
Começo relembrando as arquiteturas EBI e Ports & Adapters. Ambos fazem uma separação explícita de qual é o código interno da aplicação, qual é externo e qual é usado para conectar o código interno e externo.
Além disso, a arquitetura Ports & Adapters identifica explicitamente três blocos fundamentais de código em um sistema:
- O que torna possível executar uma interface de usuário, qualquer que seja o tipo de interface de usuário;
- A lógica de negócios do sistema, ou Application Core, que é usado pela interface do usuário para realmente fazer as coisas acontecerem;
- Código de infraestrutura, que conecta o Application Core a ferramentas como banco de dados, mecanismo de busca ou APIs de terceiros.

O Application Core é o que realmente devemos nos preocupar. É o código que permite que nosso código faça o que deve fazer, é a nossa aplicacação. Ele pode usar várias interfaces de usuário (PWA, Mobile, CLI, API, …), mas o código que realmente faz o trabalho é o mesmo e está localizado no Application Core, não deve realmente importar qual IU o aciona.
Como você pode imaginar, o fluxo típico do aplicativo vai do código na interface do usuário, passando pelo Application Core até o código da infraestrutura, depois ele volta ao Application Core e, finalmente, fornece uma resposta à interface do usuário.

Ferramentas
Longe do código mais importante do nosso sistema, o Application Core, temos as ferramentas que a nossa aplicação utiliza, por exemplo, uma base de dados, um mecanismo de busca, um servidor Web ou um console CLI (embora os dois últimos também sejam mecanismos de entrega).
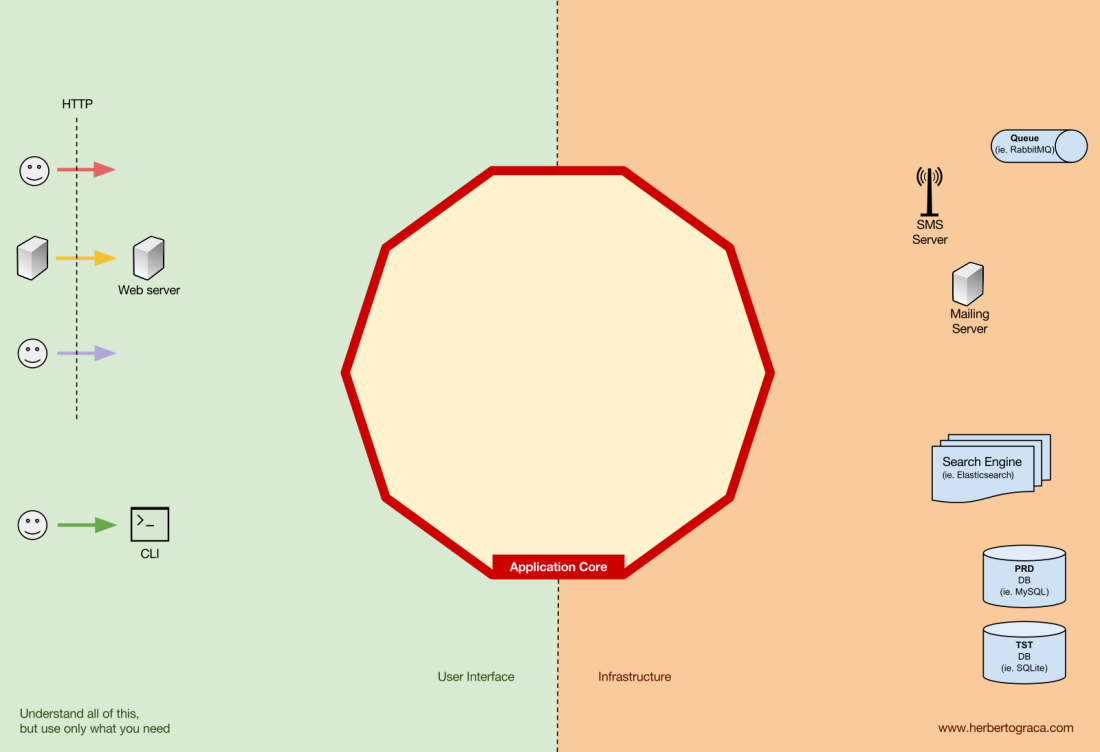
Embora possa parecer estranho colocar um console CLI no mesmo “balde” de uma banco de dados, e embora eles tenham diferentes tipos de propósitos, eles são na verdade ferramentas usadas pela aplicacação. A principal diferença é que, enquanto o console CLI e o servidor da web são usados para instruir nossa aplicacação a fazer algo, o mecanismo de banco de dados é instruído por nossa aplicacação a fazer algo. Essa é uma distinção muito relevante, pois tem fortes implicações em como construímos o código que conecta essas ferramentas ao Application Core.
Conectando as ferramentas e mecanismos de entrega ao Application Core
As unidades de código que conectam as ferramentas ao Application Core são chamadas de Adapters (Ports & Adapters Architecture). Os Adapters são aqueles que implementam efetivamente o código que permitirá que a lógica de negócios se comunique com uma ferramenta específica e vice-versa.
Os Adapters que instruem nossa aplicacação a fazer algo são chamados de Primary or Driving Adapters (Adaptadores Primários ou de Acionamento), enquanto aqueles que são instruídos por nossa aplicacação a fazer algo são chamados de Secondary or Driven Adapters (Adaptadores Secundários ou Acionados).
Ports (Portas)
Esses Adapters, no entanto, não são criados aleatoriamente. Eles são criados para se ajustar a um ponto de entrada muito específico para o Application Core, uma porta. Uma Port nada mais é do que uma especificação de como a ferramenta pode usar o Application Core ou como ela é usada pelo Application Core. Na maioria das linguagens e em sua forma mais simples, esta especificação, a porta, será uma interface, mas na verdade pode ser composta de várias interfaces e DTOs.
É importante observar que as Ports (interfaces) pertencem à lógica de negócios, enquanto os Adapters pertencem à parte externa. Para que esse padrão funcione como deveria, é de extrema importância que as Ports sejam criadas para atender às necessidades do Application Core e não simplesmente imitar as APIs das ferramentas.
Adaptadores primários ou de acionamento
Os Adaptadores primários se embrulham em uma Porta e a usam para informar ao Application Core o que fazer. Eles traduzem tudo o que vem de um mecanismo de entrega em uma chamada de método no Application Core.

Em outras palavras, nossos Adaptadores Primários são Controllers ou comandos de console que são injetados em seu construtor com algum objeto cuja classe implementa a interface (Port) que o controlador ou comando de console requer.
Em um exemplo mais concreto, uma Port pode ser uma interface de serviço ou uma interface de repositório que um controlador requer. A implementação concreta do Serviço, Repositório ou Consulta é então injetada e usada no Controlador.
Como alternativa, uma porta pode ser uma interface de barramento de comando ou barramento de consulta. Neste caso, uma implementação concreta do Command Bus ou Query Bus é injetada na Controller, que então constrói um Command ou Query e o passa para o barramento relevante.
Adaptadores secundários ou acionados
Ao contrário dos Adaptadores primários, que envolvem uma porta, os Adapters secundários implementam uma porta, uma interface e, em seguida, são injetados no Application Core, onde quer que a porta seja necessária (type-hinted).

Por exemplo, vamos supor que temos uma aplicação ingênua que precisa manter os dados. Assim, criamos uma interface de persistência que atende às suas necessidades, com um método para salvar um array de dados e um método para deletar uma linha em uma tabela por seu ID. A partir daí, sempre que nossa aplicação precisar salvar ou deletar dados, iremos pedir para o seu construtor um objeto que implemente a interface de persistência que definimos.
Agora criamos um adaptador específico para MySQL que implementará essa interface. Ele terá os métodos para salvar um array e deletar uma linha em uma tabela, e o injetaremos onde quer que a interface de persistência seja necessária.
Se em algum ponto decidirmos mudar o fornecedor do banco de dados, digamos para PostgreSQL ou MongoDB, precisamos apenas criar um novo adaptador que implemente a interface de persistência e seja específico para PostgreSQL, e injetar o novo adaptador em vez do antigo.
Inversão de controle
Uma característica a ser observada sobre esse padrão é que os Adaptadores dependem de uma ferramenta específica e de uma Porta específica (por meio da implementação de uma interface). Mas nossa lógica de negócios depende apenas da Porta (interface), que é projetada para atender às necessidades da lógica de negócios, portanto, não depende de um adaptador ou ferramenta específica.
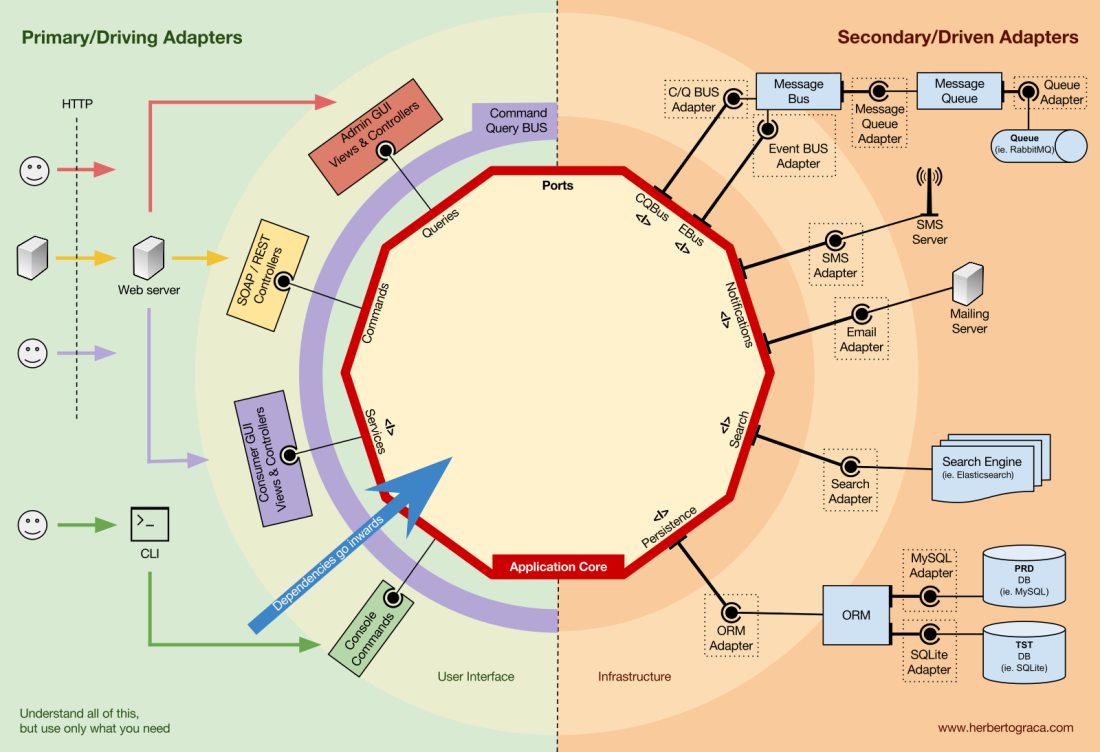
Isso significa que a direção das dependências é em direção ao centro, é a inversão do princípio de controle no nível arquitetural.
Embora, novamente, seja de extrema importância que as Portas sejam criadas para atender às necessidades do Application Core e não simplesmente imitar as APIs das ferramentas.
Organização do Application Core
A Onion Architecture pega as camadas DDD e as incorpora à arquitetura de Ports & Adapters. Essas camadas têm o objetivo de trazer alguma organização para a lógica de negócios, o interior do “hexágono” de Ports & Adapters, e assim como em Ports & Adapters, a direção das dependências é voltada para o centro.
Camada da Aplicação
Os casos de uso são os processos que podem ser acionados em nosso Application Core por uma ou várias interfaces de usuário em nossa aplicacação. Por exemplo, em um CMS, poderíamos ter a UI do aplicativo real usada pelos usuários comuns, outra UI independente para os administradores do CMS, outra UI CLI e uma API da web. Essas UIs podem acionar casos de uso que podem ser específicos para um deles ou reutilizados por vários deles.
Os casos de uso são definidos na Camada da Aplicação, a primeira camada fornecida pelo DDD e usada pela Onion Architecture.

Esta camada contém Application Services (Serviços da Aplicação) e suas interfaces como cidadãos de primeira classe, mas também contém as interfaces de Ports & Adapters (Ports) que incluem interfaces ORM, interfaces de mecanismos de busca, interfaces de mensagens e assim por diante. No nosso caso, estamos utilizando um Command Bus e/ou um Query Bus, esta camada é onde pertencem os respectivos Handlers para os Commands e Queries.
O Application Services e/ou Command Handlers contêm a lógica para desdobrar um caso de uso, um processo de negócios. Normalmente, seu caminho é:
- Use um repositório para encontrar uma ou várias entidades;
- Diga a essas entidades para fazer alguma lógica de domínio;
- E use o repositório para persistir as entidades novamente, salvando efetivamente as alterações de dados.
Os Command Handlers (manipuladores de comando) podem ser usados de duas maneiras diferentes:
- Eles podem conter a lógica real para realizar o caso de uso;
- Eles podem ser usados como meras peças de fiação em nossa arquitetura, recebendo um Command e simplesmente acionando a lógica existente em um Application Service.
Qual abordagem usar depende do contexto, por exemplo:
- Já temos os serviços da aplicação em vigor e agora estamos adicionando um barramento de comando?
- O Command Bus permite especificar qualquer classe/método como um Handler, ou eles precisam estender/implementar classes/interfaces existentes?
Essa camada também contém o acionamento de eventos da aplicação (trigger of Application Events), que representam algum resultado de um caso de uso. Esses eventos acionam a lógica que é um efeito colateral de um caso de uso, como enviar e-mails, notificar uma API de terceiros, enviar uma notificação push ou até mesmo iniciar outro caso de uso que pertence a um componente diferente da aplicação.
Camada de Domínio
Mais para dentro, temos a Camada de Domínio. Os objetos nesta camada contêm os dados e a lógica para manipular esses dados, que são específicos do próprio Domínio e são independentes dos processos de negócios que acionam essa lógica, eles são independentes e desconhecem completamente a Camada de Aplicação.

Serviços de Domínio
Como mencionei acima, a função de um Serviço da Aplicação (Application Service) é:
- Usar um repositório para encontrar uma ou várias entidades;
- Dizer a essas entidades para fazer alguma lógica de domínio;
- E usar o repositório para persistir as entidades novamente, salvando efetivamente as alterações de dados.
No entanto, às vezes encontramos alguma lógica de domínio que envolve entidades diferentes, do mesmo tipo ou não, e sentimos que essa lógica de domínio não pertence às próprias entidades, sentimos que essa lógica não é sua responsabilidade direta.
Portanto, nossa primeira reação pode ser colocar essa lógica fora das entidades, em um Application Service. No entanto, isso significa que essa lógica de domínio não será reutilizável em outros casos de uso: a lógica de domínio deve ficar fora da camada da aplicacação!
A solução é criar um Serviço de Domínio (Domain Service), que tem a função de receber um conjunto de entidades e realizar algumas lógicas de negócio nelas. Um Serviço de Domínio pertence à Camada de Domínio e, portanto, não sabe nada sobre as classes da Camada da Aplicação, como os Serviços de Aplicacação ou Repositórios. Por outro lado, pode utilizar outros Serviços de Domínio e, claro, os objetos Modelo de Domínio.
Modelo de Domínio
Bem no centro, não dependendo de nada fora dele, está o Modelo de Domínio, que contém os objetos de negócios que representam algo no domínio. Exemplos desses objetos são, em primeiro lugar, Entidades, mas também Objetos de Valor, Enums e quaisquer objetos usados no Modelo de Domínio.
O Modelo de Domínio também é onde os Eventos de Domínio “vivem”. Esses eventos são acionados quando um conjunto específico de dados muda e eles carregam essas mudanças com eles. Em outras palavras, quando uma entidade muda, um Evento de Domínio é acionado e carrega os novos valores das propriedades alteradas. Esses eventos são perfeitos, por exemplo, para serem usados no Event Sourcing.
Componentes
Até agora, estivemos segregando o código com base em camadas, mas essa é a segregação de código de baixa granularidade. A segregação grosseira de código é pelo menos tão importante e se trata de segregar o código de acordo com subdomínios e contextos limitados (Bounded Context), seguindo as ideias de Robert C. Martin expressas em Screaming Architecture. Isso é frequentemente referido como “Pacote por recurso” ou “Pacote por componente” em oposição a “Pacote por camada”, e é muito bem explicado por Simon Brown em sua postagem no blog “Package by component and architecturally-aligned testing“:
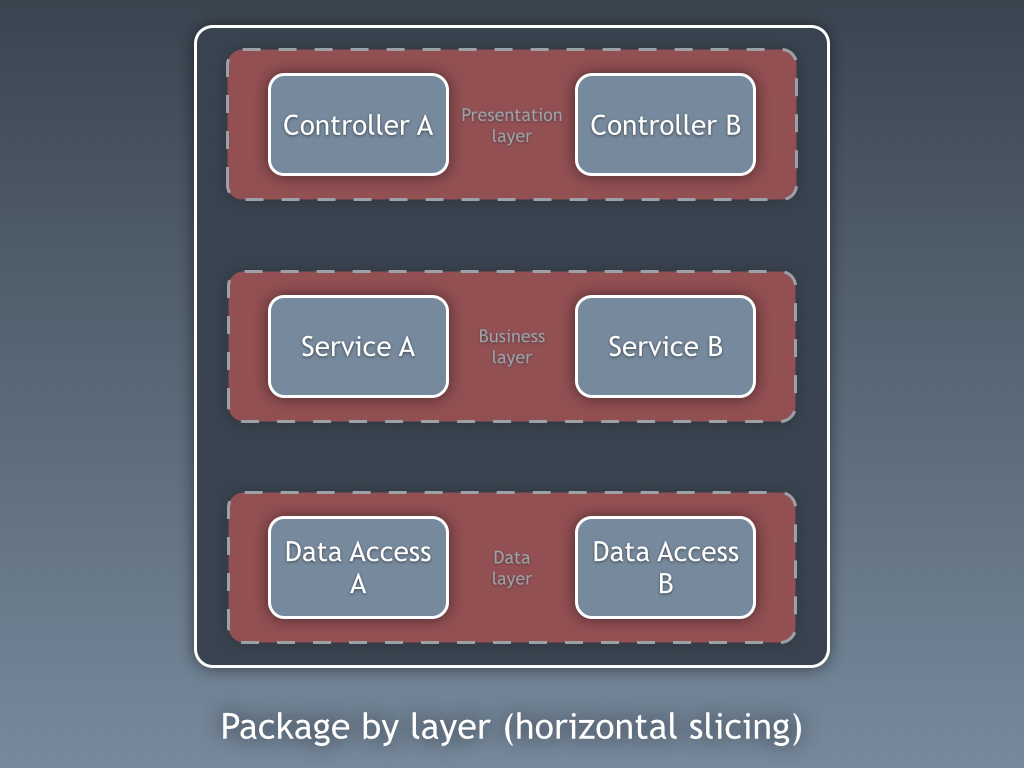
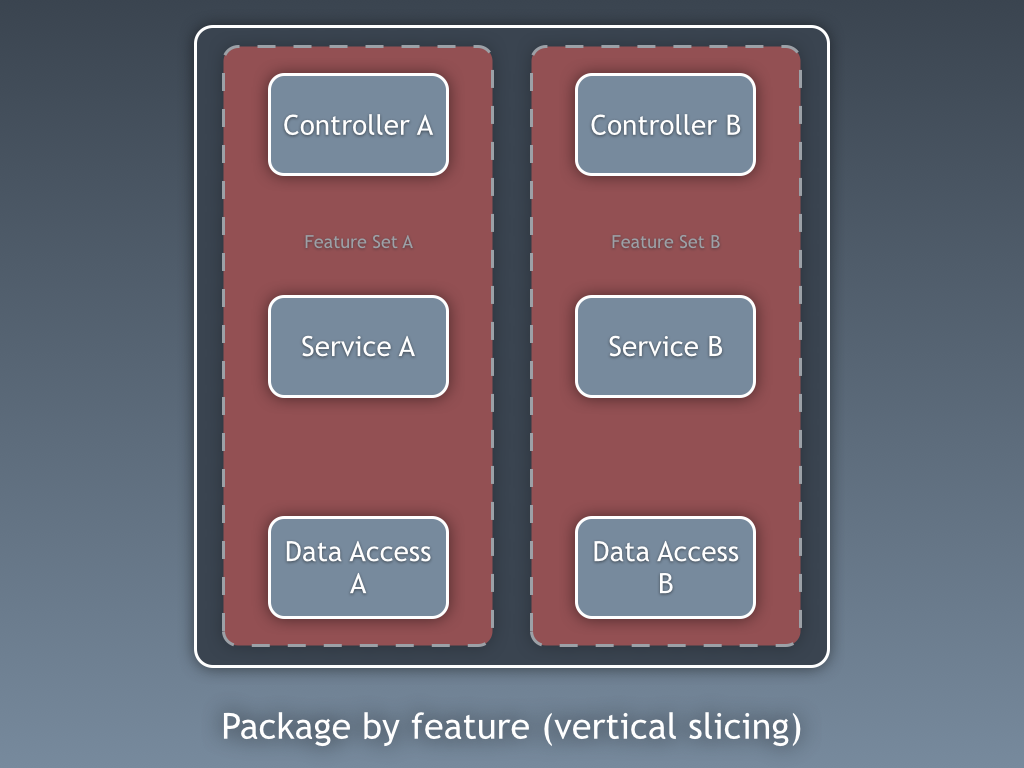
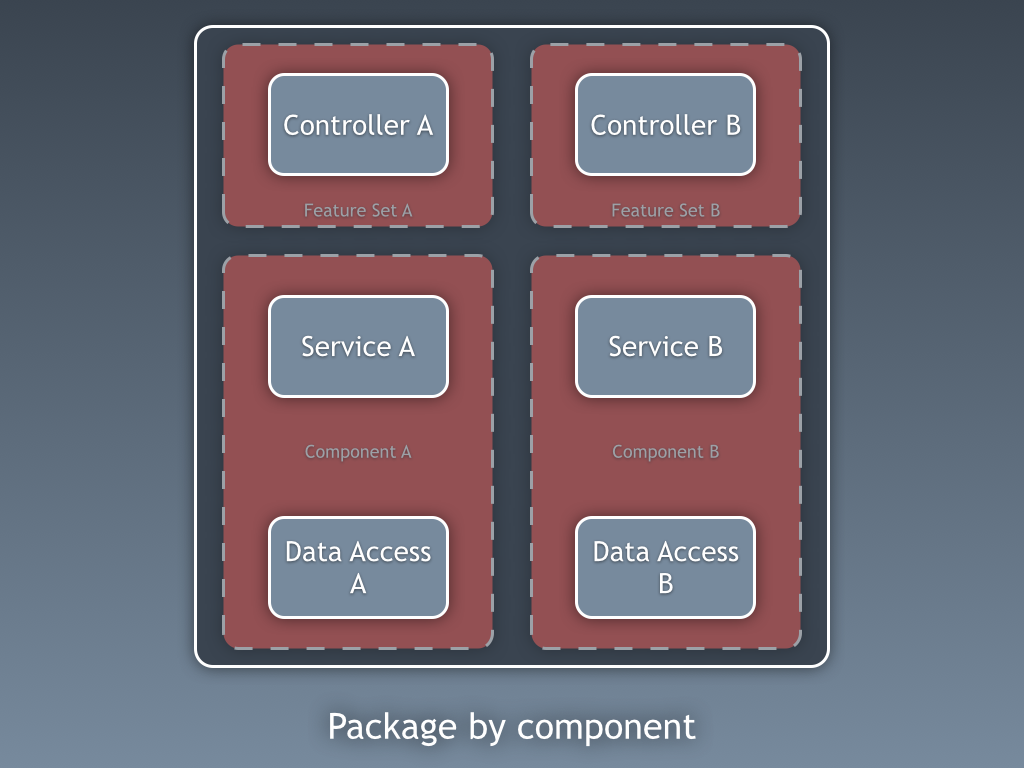
Eu sou um defensor da abordagem “Pacote por componente” e, pegando no diagrama de Simon Brown sobre Pacote por componente, eu descaradamente o mudaria para o seguinte:
Essas seções de código são transversais às camadas descritas anteriormente, elas são os componentes da nossa aplicação. Exemplos de componentes podem ser Faturamento, Usuário, Revisão ou Conta, mas estão sempre relacionados ao domínio. Contextos limitados como autorização e/ou autenticação devem ser vistos como ferramentas externas para as quais criamos um adaptador e nos escondemos atrás de algum tipo de porta.
Dissociando os componentes
Assim como as unidades de código de baixa granularidade (classes, interfaces, características, mixins, …), também as unidades de código de baixa granularidade (componentes) se beneficiam de baixo acoplamento e alta coesão.
Para desacoplar classes, fazemos uso de injeção de dependência, injetando dependências em uma classe ao invés de instanciar elas dentro da classe, e Inversão de dependência, fazendo a classe depender de abstrações (interfaces e/ou classes abstratas) em vez de classes concretas. Isso significa que a classe dependente não tem conhecimento sobre a classe concreta que vai usar, não tem referência ao nome de classe totalmente qualificado das classes das quais depende.
Da mesma forma, ter componentes completamente desacoplados significa que um componente não tem conhecimento direto de qualquer outro componente. Em outras palavras, ele não faz referência a nenhuma unidade de código de baixa granularidade de outro componente, nem mesmo interfaces! Isso significa que injeção de dependência e inversão de dependência não são suficientes para desacoplar componentes; precisaremos de algum tipo de construção arquitetônica. Podemos precisar de eventos, um kernel compartilhado, consistência eventual e até mesmo um serviço de descoberta!
Lógica de disparo em outros componentes
Quando um de nossos componentes (componente B) precisa fazer algo sempre que algo acontece em outro componente (componente A), não podemos simplesmente fazer uma chamada direta do componente A para uma classe/método no componente B porque A seria então acoplado para B.
No entanto, podemos fazer com que A use um despachante de eventos para despachar um evento da aplicação que será entregue a qualquer componente que o escuta, incluindo B, e o ouvinte de evento em B acionará a ação desejada. Isso significa que o componente A dependerá de um despachante de eventos, mas será desacoplado de B.
No entanto, se o próprio evento “vive” em A, isso significa que B sabe sobre a existência de A, ele é acoplado a A. Para remover essa dependência, podemos criar uma biblioteca com um conjunto de funcionalidades centrais da aplicação que serão compartilhadas entre todos os componentes, o Kernel Compartilhado.
Isso significa que os componentes dependerão do Kernel Compartilhado, mas serão separados um do outro. O Kernel Compartilhado conterá funcionalidades como eventos de aplicativo e domínio, mas também pode conter Specification objects e tudo o que faz sentido compartilhar, tendo em mente que deve ser o mínimo possível porque qualquer mudança no Kernel Compartilhado afetará todos os componentes do a aplicação. Além disso, se tivermos um sistema poliglota, digamos um ecossistema de micro-serviços onde eles são escritos em diferentes idiomas, o Kernel Compartilhado precisa ser agnóstico de linguagem para que possa ser compreendido por todos os componentes, qualquer que seja a linguagem em que foram escritos. Por exemplo, em vez do Kernel compartilhado que contém uma classe de evento, ele conterá a descrição do evento (ou seja, nome, propriedades, talvez até métodos, embora estes sejam mais úteis em um Specification objects) em uma linguagem agnóstica como JSON, para que todos os componentes/microsserviços possam interpretá-lo e talvez até gerar automaticamente suas próprias implementações concretas.
Leia mais sobre isso em minha postagem de acompanhamento: Mais do que camadas concêntricas.

Essa abordagem funciona tanto em aplicatições monolíticas quanto em aplicativos distribuídos, como ecossistemas de microsserviços. No entanto, quando os eventos só podem ser entregues de forma assíncrona, para contextos em que o acionamento da lógica em outros componentes precisa ser feito imediatamente, essa abordagem não será suficiente! O componente A precisará fazer uma chamada HTTP direta para o componente B. Neste caso, para ter os componentes desacoplados, precisaremos de um serviço de descoberta para o qual A perguntará para onde deve enviar a solicitação para acionar a ação desejada ou, alternativamente, fazer a solicitação para o serviço de descoberta que pode procurá-la para o serviço relevante e, eventualmente, retornar uma resposta ao solicitante. Essa abordagem acopla os componentes ao serviço de descoberta, mas os mantém separados uns dos outros.
Obtendo dados de outros componentes
Ao meu ver, um componente não tem permissão para alterar dados que não seja de sua propriedade, mas tudo bem ele consultar e usar quaisquer dados.
Armazenamento de dados compartilhado entre componentes
Quando um componente precisa usar dados que pertencem a outro componente, digamos que um componente de faturamento precise usar o nome do cliente que pertence ao componente de contas, o componente de faturamento conterá um objeto de consulta que consultará o armazenamento de dados para esses dados. Isso significa simplesmente que o componente de faturamento pode saber sobre qualquer conjunto de dados, mas deve usar os dados que não possui como somente leitura, por meio de consultas.
Armazenamento de dados segregado por componente
Nesse caso, o mesmo padrão se aplica, mas temos mais complexidade no nível de armazenamento de dados. Ter componentes com seu próprio armazenamento de dados significa que cada armazenamento de dados contém:
- Um conjunto de dados que possui e é o único que pode ser alterado, tornando-se a única fonte da verdade;
- Um conjunto de dados que é uma cópia dos dados de outros componentes, que não pode ser alterado por conta própria, mas é necessário para a funcionalidade do componente e precisa ser atualizado sempre que for alterado no componente proprietário.
Cada componente criará uma cópia local dos dados de que precisa de outros componentes, para ser usada quando necessário. Quando os dados mudam no componente que os possui, esse componente do proprietário aciona um evento de domínio carregando as mudanças de dados. Os componentes que mantêm uma cópia desses dados ouvirão esse evento de domínio e atualizarão sua cópia local de acordo.
Fluxo de Controle
Como eu disse acima, o fluxo de controle vai, é claro, do usuário para o Application Core, para as ferramentas de infraestrutura, de volta para o Application Core e, finalmente, de volta para o usuário. Mas como exatamente as classes se encaixam? Quais dependem de quais? Como os compomos?
Seguindo Uncle Bob, em seu artigo sobre Arquitetura Limpa, tentarei explicar o fluxo de controle com diagramas UMLish…
Sem um barramento de Command/Query
No caso de não utilizarmos um Command Bus, os Controller dependerão de um Application Service ou de um Query Object. Esqueci que o DTO que uso para retornar dados da consulta, então o adicionei agora. Obrigado MorphineAdministered que indicou isso para mim.
No diagrama acima, usamos uma interface para o Application Service, embora possamos argumentar que ela não é realmente necessária, uma vez que o Application Service é parte do código da nossa aplicação e não queremos trocá-lo por outra implementação, embora possamos refatorá-lo inteiramente.
O Query Object conterá uma consulta otimizada que simplesmente retornará alguns dados brutos para serem mostrados ao usuário. Esses dados serão retornados em um DTO que será injetado em um ViewModel. Este ViewModel pode ter alguma lógica de exibição nele e será usado para preencher uma View.
O Application Service, por outro lado, conterá a lógica do caso de uso, a lógica que acionaremos quando quisermos fazer algo no sistema, em vez de simplesmente visualizar alguns dados. Os Serviços de Aplicativo dependem de Repositórios que retornarão a(s) Entidade(s) que contêm a lógica que precisa ser acionada. Também pode depender de um Domain Service para coordenar um processo de domínio em várias entidades, mas dificilmente é o caso.
Depois de desdobrar o caso de uso, a Application Service pode querer notificar todo o sistema que aquele caso de uso aconteceu, caso em que também dependerá de um despachante de eventos para acionar o evento.
É interessante notar que colocamos interfaces tanto no mecanismo de persistência quanto nos repositórios. Embora possa parecer redundante, eles têm finalidades diferentes:
- A interface de persistência é uma camada de abstração sobre o ORM para que possamos trocar o ORM que está sendo usado sem alterações no Application Core.
- A interface do repositório é uma abstração do próprio mecanismo de persistência. Digamos que queremos mudar do MySQL para o MongoDB. A interface de persistência pode ser a mesma e, se quisermos continuar usando o mesmo ORM, até o adaptador de persistência permanecerá o mesmo. No entanto, a linguagem de consulta é completamente diferente, então podemos criar novos repositórios que usam o mesmo mecanismo de persistência, implementar as mesmas interfaces de repositório, mas construir as consultas usando MongoDB em vez de SQL.
Com um barramento de Command/Query
No caso de nossa aplicação utilizar um Command/Query Bus, o diagrama permanece praticamente o mesmo, exceto que a Controller agora depende do Bus e de um Command ou Query. Ele irá instanciar o Command/Query e passá-lo para o Bus, que encontrará o Handler apropriado para receber e manipular o comando.
No diagrama abaixo, o Command Handler usa uma Application Service. No entanto, isso nem sempre é necessário; na verdade, na maioria dos casos, o Handler conterá toda a lógica do caso de uso. Precisamos apenas extrair a lógica do Handler para uma Application Service separada se precisarmos reutilizar essa mesma lógica em outro Handler.
Você deve ter notado que não há dependência entre o Bus e o Command, as Queries ou os Handler. Isso ocorre porque eles devem, de fato, não estar cientes uns dos outros para permitir um bom desacoplamento. A maneira como o barramento saberá qual Handler deve tratar qual Command, ou Query, deve ser configurado com mera configuração.
Como você pode ver, em ambos os casos todas as setas, as dependências, que cruzam a fronteira do Application Core, apontam para dentro. Como explicado antes, essa é uma regra fundamental da Arquitetura de Ports e Adapters, Arquitetura Onion e Arquitetura Limpa.
Conclusão
O objetivo, como sempre, é ter uma base de código desacoplada e altamente coesa, para que as alterações sejam fáceis, rápidas e seguras de fazer.
“Os planos não valem nada, mas o planejamento é tudo.” - Eisenhower
Este infográfico é um mapa conceitual. Conhecer e compreender todos esses conceitos nos ajudará a planejar uma arquitetura saudável, uma aplicaticação saudável. No entanto:
“O mapa não é o territorio.” - Alfred Korzybski
O que significa que tudo isso, são apenas diretrizes! A aplicação é o território, a realidade, o caso de uso concreto onde precisamos aplicar nosso conhecimento, e é isso que vai definir como será a arquitetura real!
Precisamos entender todos esses padrões, mas também sempre precisamos pensar e entender exatamente o que nossa aplicação precisa, até onde devemos ir em prol do desacoplamento e da coesão. Essa decisão pode depender de muitos fatores, começando com os requisitos funcionais do projeto, mas também pode incluir fatores como o prazo para construir a aplicação, a vida útil da aplicação, a experiência da equipe de desenvolvimento e assim por diante.
É isso, é assim que eu entendo tudo. É assim que racionalizo na minha cabeça. Expandi essas ideias um pouco mais em uma postagem de acompanhamento: More than concentric layers.
No entanto, como tornamos tudo isso explícito na base de código? Esse é o assunto de um dos meus próximos posts: como refletir a arquitetura e o domínio, no código. Por último, mas não menos importante, obrigado ao meu colega Francesco Mastrogiacomo, por me ajudar a deixar meu infográfico bonito. 🙂

Comentários